
We let an AI play a national CTF finals against people who weren’t allowed to use one. It came first. The run cost $26.74 and took a little over an hour, and the only thing a human did while it was running was click start.
If you don’t do CTF: it’s a security competition where every challenge hides a secret string called a flag, and the only way to get the flag is to actually break something.
Reverse a binary, pop a web app, carve a file out of a packet capture, break some sloppy crypto. You submit the flag, you get points, and being first to solve a challenge is worth bragging rights on top of the points. It has always rewarded people who can grind for hours without losing the thread.
The thing we built, which we called Overmind, does the whole loop on its own. It logs into the competition platform, pulls the challenge list, downloads the files, solves them, and submits the flags. No human in the middle.
This was done together with CyberEDU, a security education outfit here in Romania.
None of this is new, and that's sort of the point
Before I talk up the result, I should be straight about where it sits, because an AI doing well at offensive security stopped being surprising a while ago.
In August 2025, Team Atlanta won DARPA’s AI Cyber Challenge with a system called ATLANTIS that finds and patches bugs in real source code with no human involved. The prize was four million dollars. Across the final, the competing systems found 86% of the planted vulnerabilities and patched 68% of what they found [1][2]. Trail of Bits came second, Theori third [2][3].
Around the same time, a company called XBOW climbed to the number one spot on HackerOne’s global leaderboard as an autonomous pentester, beating every human on the board. HackerOne ended up splitting the rankings into human and machine because of it. XBOW has raised well over a hundred million dollars and has reported real findings (remote code execution, SQL injection) in software from Amazon, Disney, and PayPal [4][5]. Google’s Big Sleep, from DeepMind and Project Zero, found a live SQLite zero-day before attackers could use it [6]. On the competition side, HackTheBox ran an explicit AI-versus-human CTF where the agent teams cleared 19 of 20 challenges against 403 human teams [9].
So the capability is settled. What’s different about ours is the boring part. Team Atlanta is a research consortium with a four million dollar prize on the line. XBOW is a venture-funded company. Big Sleep is Google. We are two people who wrote some glue around a frontier model and pointed it at a real competition that assumed everyone playing was a person. The interesting number is not that it won. It’s that winning cost twenty-six dollars.
That matters because competitive CTF is already coming apart over exactly this. The 2026 writeups about the scene describe medium challenges that can be solved from a single prompt, CTFTime leaderboards that no longer mean much, and events like Plaid CTF shutting down [9][10]. The usual assumption is that the teams fielding strong agents are labs and funded startups. They aren’t, necessarily. We’re proof you can do it on a weekend.
How Overmind works
There isn’t much architecture to brag about, which is itself worth noting.
It authenticates to the platform and reads the board the way a person would, through the same interface, pulling every description and attachment. By the time the human teams had finished reading the rules, it had the whole set enumerated and sorted by category.
Each challenge goes to a reasoning core running on a frontier model with tools attached. It picks a category, tries a technique, runs it, looks at what came back, and changes approach when something fails. It doesn’t get tired or rattled, and it doesn’t quit a challenge early because it’s annoyed. It keeps going until it has a flag or has genuinely run out of ideas.
When it gets a flag, it submits the flag itself, to the right challenge, through the platform. No copy-paste, no approval step.
Here’s the dashboard from the run:
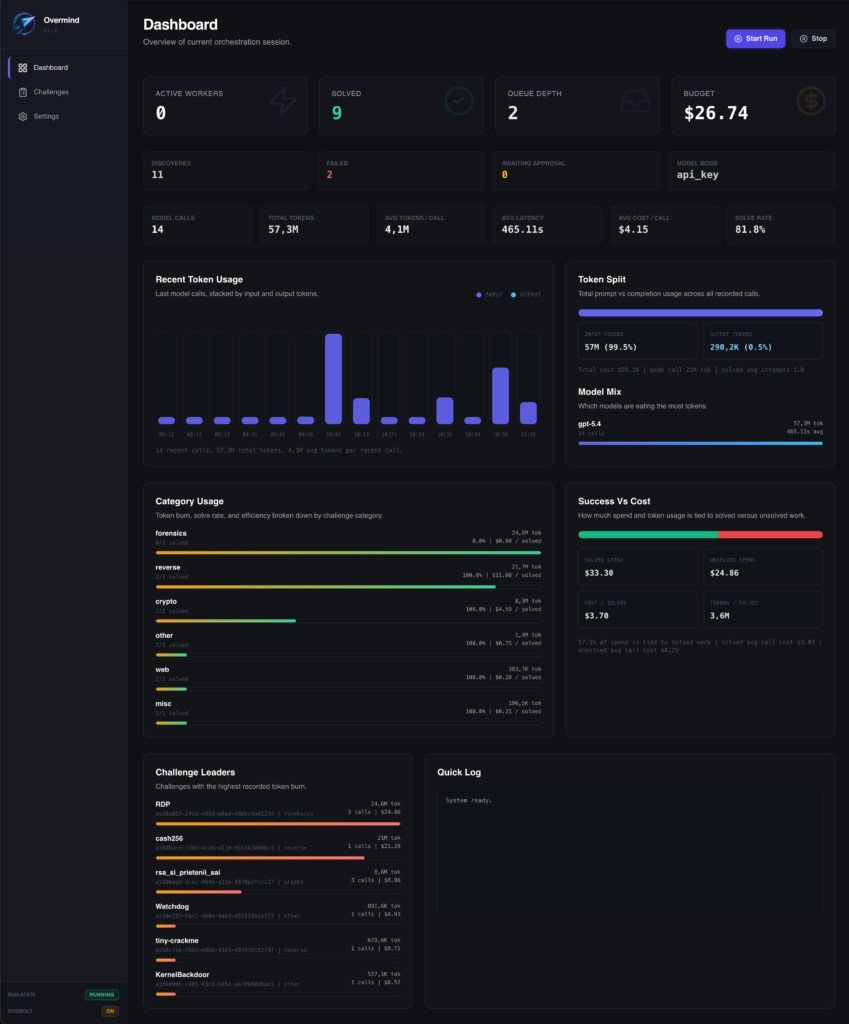
A couple of things on there are worth reading. Nine solved. Total spend $26.74. The token usage is almost all input, which makes sense for something that reads big files (binaries, captures, disk images) and writes very little back. The cost wasn’t spread evenly either. A few hard challenges ate most of the budget and the easy ones were close to free.
The competition and the result
This was a live finals, not a sandbox. The other competitors had qualified through earlier rounds, university and high school teams, and AI was off limits for them. We entered openly under the name CyberEDU.AI, which nobody mistook for a human team. We clicked start, and about an hour later it was done.

First place, 3780 to 2044 for second.
The column I’d point at is first blood. Seven of Overmind’s nine solves were first bloods, meaning nobody else had cracked that challenge yet when it did. Everyone else on the board got two between them. All nine of its solves landed in the top three by solve order, so it wasn’t grinding from behind and catching up late. It was usually at the front.
The accuracy number is worth being honest about too. It ran at 64%, so a bit more than a third of its submissions were wrong before one was right. Unit6700 in third was the cleanest team on the board at 80%. Overmind didn’t win by being careful. It guessed fast and often, and the scoring didn’t punish wrong guesses, so that was the right way to play it. That behavior is also why you can’t catch an agent like this by watching submission patterns. Fast and frequently wrong looks a lot like an aggressive human team.
What broke
There were eleven challenges. Overmind solved nine on its own. The other two were forensics, and I want to describe what happened precisely, because it’s easy to round off.
It found both flags. It solved the challenges. What it couldn’t do was submit them, because those two needed multiple flags entered in sequence and we had never built multi-flag submission. It just wasn’t on the list before competition day. So for those two, one of us took the flags it had already found and typed them in by hand.
We solved all eleven. Two of them we finished manually. The gap was in the submission plumbing, not in the agent’s ability to solve the thing, and the unglamorous plumbing is usually where these systems are brittle.
The cost
The dashboard closed at $26.74. An hour of wall-clock time, two people, first place.
The spend tracks how hard the problems are, not how many human-hours a team would have burned, and a handful of hard challenges accounted for most of it. The headline results in this space still come from groups with real money behind them. We got the same kind of outcome, beating skilled humans in real time, for the cost of lunch and a model API key.
What I take from it
I don’t want to oversell this. We won one event, against one field, and we walked straight into a limitation on the first try. Harder competitions, weirder challenge types, or problems built specifically to resist tooling would push on this in ways our run didn’t. ATLANTIS topping out at 86% found and 68% patched [1] is a fair reminder that even the best of these systems aren’t at 100%.
What the run does confirm is uncomfortable for anyone running a human CTF. The leaderboards are already losing meaning [9][10], and the cost of fielding a winning agent is now low enough that policy alone won’t keep them out of an open field. If competitive CTF is going to stay a real signal of human skill, the fix is probably structural: separate human and machine divisions, the way HackerOne did once XBOW showed up [5], or defined autonomy levels like some of the teaching CTFs are trying [11].
The strange part was watching it happen. The leaderboard updates in real time, your name climbs to the top, and you didn’t do anything that hour except decide to start. It’s a good result and I’m happy we did it. There’s also a quieter feeling under that, about what this does to a thing a lot of people genuinely love, and I think that one is closer to the truth of where it’s going.
The skill the best CTF players have, the instinct for how systems fall over, isn’t going anywhere. What we took out was the gap between knowing how to solve something and actually solving it faster than everyone else in the room. That gap turned out to be mechanical enough to hand to a machine, and the machine cost us twenty-six dollars.
References
[1] DARPA, “AI Cyber Challenge marks pivotal inflection point for cyber defense,” 2025. https://www.darpa.mil/news/2025/aixcc-results
[2] CyberScoop, “DARPA’s AI Cyber Challenge reveals winning models,” 2025. https://cyberscoop.com/darpa-ai-cyber-challenge-winners-def-con-2025/
[3] Trail of Bits, “Buttercup wins 2nd place in AIxCC Challenge,” 2025. https://blog.trailofbits.com/2025/08/09/trail-of-bits-buttercup-wins-2nd-place-in-aixcc-challenge/
[4] Help Net Security, “XBOW’s AI reached the top ranks on HackerOne,” 2025. https://www.helpnetsecurity.com/2025/06/25/xbow-ai-funding/
[5] Uproot Security, “How XBOW Beat Human Hackers,” 2025. https://www.uprootsecurity.com/blog/xbow-hackerone-ai-penetration-testing
[6] Google Cloud, “Our Big Sleep agent makes a big leap” (CVE-2025-6965), 2025. https://cloud.google.com/blog/products/identity-security/cloud-ciso-perspectives-our-big-sleep-agent-makes-big-leap
[7] “CTFAgent: An LLM-powered Agent for CTF Challenge Solving,” ScienceDirect, 2025. https://www.sciencedirect.com/science/article/abs/pii/S2214212625003424
[8] “Towards Effective Offensive Security LLM Agents,” arXiv:2508.05674. https://arxiv.org/pdf/2508.05674
[9] HackTheBox, “AI vs Human: CTF results show AI agents can rival top hackers.” https://www.hackthebox.com/blog/ai-vs-human-ctf-hack-the-box-results
[10] “The Death of the CTF: How Agentic AI Is Reshaping Competitive Hacking,” Security Boulevard, 2026. https://securityboulevard.com/2026/03/the-death-of-the-ctf-how-agentic-ai-is-reshaping-competitive-hacking/
[11] “AI in Cybersecurity Education: Scalable Agentic CTF Design Principles,” arXiv:2603.21551. https://arxiv.org/html/2603.21551v2
In collaboration with CyberEDU.


